


January-February 2025 Progress in Guaranteed Safe AI
Proving the Coding Interview, R1, a job, and yet another ARIA solicitation

Ok this one got too big, I’m done grouping two months together after this.
BAIF wants to do user interviews to prospect formal verification acceleration projects, reach out if you’re shipping proofs but have pain points!
This edition has a lot of my takes, so I should warn you that GSAI is a pretty diverse field and I would expect all my colleagues in it to have substantial disagreement with at least one take in each issue of the newsletter. Prompt the language model to insert the standard boilerplate disclaimer that views are my own, not those of my colleagues, my employer nor my mom.
If you're just joining us, background on GSAI here.
Formal Verification is Overrated (lightning talk)
Zac makes three sound points which are not cruxes for me. Part of what Nora’s post is doing is responding to this with her take, which differs from mine.
Point one: weights are intractable
Formal verification of the learned component itself is gonna be a nonstarter on nontoy problems for computational cost reasons. We saw last year that a “proof” of the correctness of a function a transformer implements is subcubic in d_vocab, at least a little worse than quadratic. I agree with Zac, which is why I avoid whitebox strategies in my day to day life. GSAI (to me) is a set of blackbox tactics, closer to control, that doesn’t depend on interpretability going particularly well. The upcoming Formalise track of ICSE separates “AI4FV” and “FV4AI” as two separate topic areas, which is obviously the right thing to do and I find half of the time when I introduce GSAI to someone this is the first point of clarification. Speaking for myself, GSAI is AI4FV without being FV4AI.
Point two: reality is complicated and unknown
This capitulates a point I’ve been making for years, which is that the world-spec gap hurts you more than the spec-implementation or spec-component gap. I think if we get arbitrary wins on GSAI agendas, but an arbitrarily unboxing superintelligence too quickly, this principle is what kills us. This principle (which needs a good name, btw) still allows you to stack your swiss cheese tower to the sky, and never says that your swiss cheese tower buys you nothing. A potential crux for me might be that if we leave our immediate successors with a tower of swiss cheese, they’ll fail to use that to escape the acute risk period for predictable reasons.
Agree that the DNA synthesis part of Tegmark and Omuhundro was a bit unhinged. Agree that insofar as Zac is responding to that paper, much “calming down” is needed cuz that paper (unlike, I think, the Toward GSAI paper) is really overstated.
Formal verification, as we know it, exists to isolate error to the spec-world gap, which realistically isolates attack surfaces to a fraction of that. This doesn’t happen for free by default, it requires defensive acceleration. My job is nines, I don’t believe in 100%. However, a significant part of Safeguarded AI is aimed at making the spec-world gap smaller, so it wouldn’t be accurate to say that GSAI stops at the spec-world gap. I think Safeguarded AI’s approach to this, which attacks the details of probabilistic world models and how they’re elicited and falsified, is more reasonable than Omohundro’s “formal specifications of physical systems” approach which is a little too bottom-up for my tastes.
I did talk to one security researcher who, after regaling me with fun tales of side channel attacks, said Omohundro’s vision of eliminating sidechannel attacks by formal verification because the model of the component goes down to physical laws like Maxwell’s equations is not as unreasonably intractable as I thought and is instead merely ambitious. So maybe I should learn basic physics.
Point three: tool AI is unstable and uncompetitive
Zac:
The final category of proposals I see under this formal verification approach is that we should use AI to develop tools and software which is formally verified. And I am broadly a fan of this, but it’s not actually a substitute for working on AI safety.
Also Zac:
The addition of a trivial for loop is the only difference between a tool and an agent (in a general sense).
I think Zac is referring to the ask to restrain AI to tool level and simply not build agents, coming mostly from Tegmark. (See FLI’s tiers. it’s possible that scaffolding more than a loop is all you need to get from tier 2 to tier 3). I just don’t think this ask is centrally related to formal verification, and is not a crux for most of the GSAI space (indeed, much of GSAI wants to leverage primitive agents such as loops). But I do agree with Zac, I think the no-agency ship has sailed and there’s no satisfying way to restrict AI to the tool level, most for competitiveness reasons.
Overrated by whom?
But also, I’d like to ask Zac how it’s “overrated” when the reception from funders (besides ARIA and FLI’s vitalikbucks) is not even lukewarm. OpenPhil is super unplugged from GSAI and not interested, SFF isn’t participating at all in spite of having some of the big position paper authors involved in the S-process. Frontier labs do a bunch of proof scaling projects, but they’re doing it just for fun / to show off / to innovate on the product, not because of any vision in particular (as far as I can tell / as far as I’ve heard). I think ARIA and the FLI Extended Cinematic Universe (i.e. BAIF) is a great place to start, we could spend more but we shouldn’t complain. Does Zac mean the current level of funding is already too high, or is he just worried about that number increasing? He does think it’s an important part of the portfolio, so I think he’s just responding to some of the over-promising (which I tend to agree with him about).
FVAPPS
4715 function signatures each with 2-5 sorry’s out theorems: a new benchmark for leetcode-style programming in Lean. Notice that I, Quinn, the newsletter author, is one of the authors.
We introduce the Formally Verified Automated Programming Progress Standards, or FVAPPS, a benchmark of 4715 samples for writing programs and proving their correctness, the largest formal verification benchmark, including 1083 curated and quality controlled samples. Previously, APPS provided a benchmark and dataset for programming puzzles to be completed in Python and checked against unit tests, of the kind seen in technical assessments in the software engineering industry. Building upon recent approaches for benchmarks in interactive theorem proving, we generalize the unit tests to Lean 4 theorems given without proof (i.e., using Lean’s “sorry” keyword).
Workshop reviewers said that the pipeline we used to generate the benchmark was also a research contribution, even though it’s the minimum viable scaffold: a loop in serial.

Say hi In Ottawa on ICSE workshop day! Special shoutout to Gas Station Manager for citing us like a week after we went public in their hallucination work.
Is this a safety paper?
I'm working on making sure we get high quality critical systems software out of early AGI. Hardened infrastructure buys us a lot in the slightly crazy story of "self-exfiltrated model attacks the power grid", but buys us even more in less crazy stories about all the software modules adjacent to AGI having vulnerabilities rapidly patched at crunchtime.
While I’m not super interested in measurement, I’m excited about this line of work as a synthetic data pipeline. It may take galaxy brained prompting and galaxy brained scaffolds to ship proofs now (if they’re elicitable at all), but by solving FVAPPS you generate synthetic data which you can put to use in finetune jobs, leading to models way better at proving, hopefully with minimal scaffolding and prompting skills. We shipped our paper to arxiv twitter the same week Goedel-LM shipped, and what they do is a kind of “finetune job in-the-loop” along these lines (i.e. using Lean as a ground truth signal).
R1 happened
With finetuning this cheap, lots of opportunities are afoot. That’s it, that’s the post. Especially of interest is that API terms of service aren’t acceptable for some critical systems vendors for compliance reasons, so running a top performing model on compute you control opens up many possibilities for them in particular.
News in automated mathematics
AlphaGeometry finally dropped a paper
For a while Google DeepMind’s results in mathematics just had a vague blog post. It’s great there are finally details in a paper, but I haven’t read it yet.
New SOTA on MiniF2F
https://goedel-lm.github.io/
The topological debate framework
I had a chance to sit down with the author at EAG. This is an exciting theory of the incentives for AIs to have good world models. These are the kind of protocols that could help us close the spec-world gap, which is going to be critical if GSAI does anything at all against arbitrary superintelligences.
Let's say that you're working on a new airplane and someone hands you a potential design. The wings look flimsy to you and you're concerned that they might snap off in flight. You want to know whether the wings will hold up before you spend money building a prototype. You have access to some 3D mechanical modeling software that you trust. This software can simulate the whole airplane at any positive resolution, whether it be 1 meter or 1 centimeter or 1 nanometer.
Ideally you would like to run the simulation at a resolution of 0 meters. Unfortunately that's not possible. What can you do instead? Well, you can note that all sufficiently small resolutions should result in the same conclusion. If they didn't then the whole idea of the simulations approximating reality would break down. You declare that if all sufficiently small resolutions show the wings snapping then the real wings will snap and if all sufficiently small resolutions show the wings to be safe then the real wings will be safe.
How small is "sufficiently small?" A priori you don't know. You could pick a size that feels sufficient, run a few tests to make sure the answer seems reasonable, and be done. Alternatively, you could use the two computationally unbounded AI agents with known utility functions that you have access to.
Debate is a little bit of a misnomer, but close enough.
https://www.lesswrong.com/posts/jCeRXgog38zRCci4K/topological-debate-framework
Atlas hiring dev for spec engineering GUI product
If we can kick the proof down to the AI and rely on the typechecker, we still want a human in the loop for writing the specification
We are developing an AI-assisted IDE for formal specification.
Autoformalization is approaching usefulness but there remains a gap for how humans establish confidence in autoformalized specs and discover issues. We're researching tools and methods to enable engineers to close this gap in real-world assurance applications. We have been prototyping and user-testing a Spec IDE and are looking to add a team member to take over primary responsibility for machine learning engineering.
This job involves developing a machine learning pipeline that powers mechanized spec engineering and review. ML plays multiple roles in the spec IDE: (1) aiding user understanding and navigation by labeling concepts within and across both mechanized and pen-and-paper spec documents, (2) detecting possible issues in the mechanization, and (3) powering a conversational assistant for users to navigate or edit specs.
Autoformalization is not itself the focus of this project, but there's an opportunity to explore autoformalization if desired. This job involves collaborating with a small remote team that brings a user-centered, product discovery mindset to this research; as such, this job also involves learning from user research, and has opportunities to run user studies if desired.
We're looking for a 20 hrs/wk contract through approximately September, but there's room for flexibility. Please let us know your contracting rate ($/hr) if you have a standard rate, else reach out to chat with us; cost will be one of our selection factors.
Contact join@atlascomputing.org with interest.
They want someone with 2 years of surface area on proof assistants like Lean and Coq and experience with ML R&D tooling.
Safeguarded AI TA1.2 and TA1.3 funding call
Video, PDF. Davidad is back with a new funding call.
Technical Area 1.1 is underway and consists of category theorists and probabilistic semantics experts designing a new stack for world models, proof certificates, and specifications. It’s the conceptual problems at the foundation of Safeguarded AI. Upon successful solutions to those problems, it becomes a fairly normal software project: a backend and a frontend.
TA1.2 is a backend. This involves structure-aware version control (previous edition of the newsletter) for eliciting world models and specs, other data structures topics for keeping track of probabilistic proof certs, and an appropriate theory of databases.
TA1.3 is a frontend. Many important stress points of Safeguarded AI require human in the loop, so we want a killer user experience. Imagine being a power plant domain expert in the near future, when AIs can do anything, but they need to elicit specs and world models from you. Hopefully it’s not too painful a process!
Both projects are investing 12 months into requirements engineering with minimal prototyping, and the new org that TA2 is planning to incubate around the end of this year will be partially shaped by those requirements.
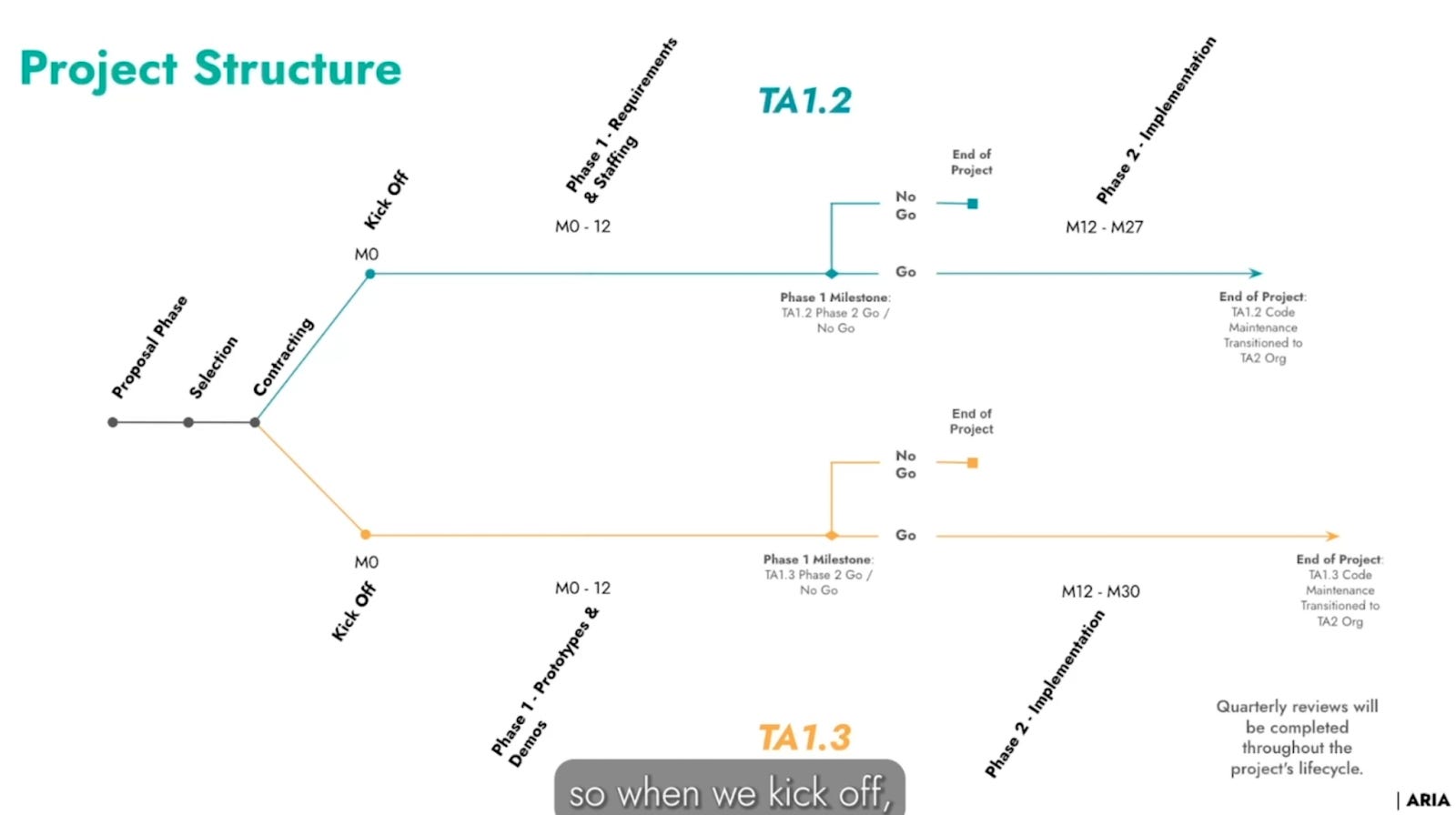
I think the microeconomics of this ambition level could be reasoned about (scrutinizing the reference class of software projects roughly this big, counting up roughly how much money was spent on them, fermstimating if this is realistic, etc.). But it’s out of scope for this newsletter.
The deadline is April 8th. It’s secretly the 9th but it’s a good habit to subtract one day when you put it in your calendar, especially since it doesn't close on an anywhere-on-earth midnight.