

September 2024 Progress in Guaranteed Safe AI
September 2024 Progress in Guaranteed Safe AI
This month we have elicitation of GPT-o1’s Lean4 skills, a worked example in self driving cars, and an interactive proof approach to correctness of learned components.

There are no benefits with paid subscription, except you get a cut of my hard earned shapley points.
As always, do reach out to inform me how the newsletter could be better, unless you want less biased and wrong quick takes. The biased and wrong quick takes are mandatory.
If you're just joining us, background on GSAI here.
Terry Tao’s mathstodon comment
“I have played a little bit with OpenAI’s new iteration of GPT”, he begins.
Let's get everyone up to speed on one of Tao's key insights: the bottlenecks to casually superb Lean4 performance are embarrassingly non-profound, chat models getting tripped up by import paths changing across Lean versions and so on. You can only choke a model by having too much code velocity in the training data for so long, but eventually that'll fall.
That may not be a great crux for Tao's use case. I think he wants to focus on the reasoning bottlenecks, and is less concerned about coding bottlenecks given reasoning. Perhaps his interest in the Lean parts is mostly Voevedsky style: what do we want? Less homework. How do we want it? With greater assurance than more homework.
You should sit and think about if you think attaining a reasoning level is easier or harder than turning that reasoning level into Lean code once attained. I sat and thought about it for 5 minutes, and I'm still not ready to make any bets. Yes, the lesson about the embarrassingly non-profound bottlenecks suggest a reasoning level is harder than translating that reasoning level into code, but on the other hand, dependent types are a really finicky way to program.
Tao reports that we've leapt from incompetent grad student to mediocre grad student, or openai has anyway. I do not know the conversion factor between units of pure maths grad student to units of GSAI-grade software developer. I'll take 1 to 1 as my prior. How about yours? Is one pure maths grad student worth of software engineering enough to accomplish your goals, if you can make copies and replace pizza/coffee with electricity?
David Manheim’s post
I liked David Manheim’s post on self driving cars as a worked example. Like we saw last month, worked examples lead to identifying cruxes clearer and faster. In this case, the commenters mostly objected about unstated assumptions, and Manheim would go on to edit more assumptions (even in the title of the post!).
Tdietterich:
Perhaps we should rename the "provable safety" area as "provable safety modulo assumptions" area and be very explicit about our assumptions. We can then measure progress by the extent to which we can shrink those assumptions.
Jacobjacob:
Very much agree. I gave some feedback along those lines as the term was coined; and am sad it didn't catch on. But of course "provable safety modulo assumptions" isn't very short and catchy...
I do like the word "guarantee" as a substitute. We can talk of formal guarantees, but also of a store guaranteeing that an item you buy will meet a certain standard. So it's connotations are nicely in the direction of proof but without, as it were, "proving too much" :)
I agree with the sentiment in the comments that provability in the sense of system safety is provability up to which assumptions, and hope to see people be more clear about this.
Models that prove their own correctness
This was june but I just found it. We’re reading it for next month’s GSAI paper club, which is convening 2024-10-17 at 10a pacific. Here, the word “proof” is in the context of “interactive proof”, or some multi-step game consisting of a prover and a verifier popular in computational complexity theory and cryptography.
How can we trust the correctness of a learned model on a particular input of interest? Model accuracy is typically measured *on average* over a distribution of inputs, giving no guarantee for any fixed input. This paper proposes a theoretically-founded solution to this problem: to train *Self-Proving models* that prove the correctness of their output to a verification algorithm V via an Interactive Proof. Self-Proving models satisfy that, with high probability over a random input, the model generates a correct output *and* successfully proves its correctness to V. The *soundness* property of V guarantees that, for *every* input, no model can convince V of the correctness of an incorrect output. Thus, a Self-Proving model proves correctness of most of its outputs, while *all* incorrect outputs (of any model) are detected by V. We devise a generic method for learning Self-Proving models, and we prove convergence bounds under certain assumptions. The theoretical framework and results are complemented by experiments on an arithmetic capability: computing the greatest common divisor (GCD) of two integers. Our learning method is used to train a Self-Proving transformer that computes the GCD *and* proves the correctness of its answer.
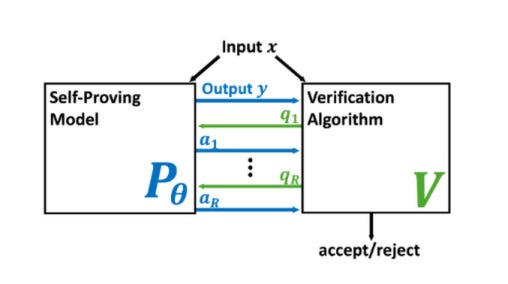
Some people in GSAI only want to gain assurance about code that AIs are writing, others want to gain assurance about the learned components themselves. If you’re in the latter camp, this proposal looks promising, but there’s a long road ahead to scale it to non-toy problems.
Types Are Not Safe
I came across this lambda conf talk solely because I used to work for the speaker– I did not check whether other lambdaconf talks are worthy of endorsement.
I'm including it in the newsletter to make sure we get on the same page about what type systems can't do. Type systems check for a pretty narrow kind of correctness. No one has lifted color blind approval of UIs to types. No one has made a PDE solver where the typechecker knows if the initial conditions you loaded in send the plane into a hillside. Lattice based access control is kinda like lifting security to a type checker, but it doesn’t know which permission sets are more or less susceptible to insider, phishing, or bribery risks. This matters, because if you cash out “formal verification” at Lean, then you've just staked it all on types, and types are not safe. I think we need a broad portfolio and several different meanings of the word “certificate”, but I keep running into people who let their guard down and hail the coming age of formally verified code generation, and if they were careful they wouldn't be so optimistic.
I tend to say that type systems are for increasing the jurisdiction of compiletime knowledge. The runtime is where your adversary has home team advantage. But many correctness notions that are in principle liftable to a sufficiently expressive typechecker are not in practice worth the trouble. Now, this is due to ergonomic bottlenecks that an LLM could steamroll over, but then you're just shifting your error/attack surface from the spec-implementation gap to “where the h!ck did this spec come from?” and of course the ever present world-spec gap.
Another title for the talk could've been “Types Lie”, but that section of the talk relies a little on advanced language extensions specific to haskell that it isn't important you understand. Some of them, like the untypeability of the type of types, is way less bad in dependently typed languages. Getting confused because you wrote some type algebra that accidentally involves uninhabited types happened to me in Lean a couple weeks ago, though.
Opportunities
Topos jobs
Both of the Oxford postdocs are concerned with world modeling and the foundations of what eventually will be specification engineering for ARIA-style Safeguarded AI.
UK’s AISI cites GSAI as an area they want to branch more into, are hiring
The UK’s AI Safety Institute is building a team for articulating positive “safety cases”, stories in which deploying models of the future is not a bad idea. They want technical talent to write these stories not just so that they’ll be calibrated but also so the team has the capacity in house to deliver on some of the empirical needs of those stories. They do plan to open an SF office over the next year, but right now you need to be onsite in London.